你正在保護程式碼
但有保護程式碼內的 AI 嗎?
文章翻譯
2026-06-24 by 高田鑑識
現代應用程式不再只靠程式碼運行,它們依賴模型、代理(agents)、嵌入向量(embeddings)、資料集,以及 MCP 伺服器等自主工具。開發人員從 Hugging Face 引入預訓練 LLM、整合開源代理框架、建立 AI 流水線的速度,已遠超安全團隊的追蹤能力。與流氓 npm 套件不同,這些元件不會清楚地出現在現有的依賴關係圖中。
對於 AppSec 團隊而言,這帶來了兩個核心問題:量與能見度。
- 量:AI 加速了開發產出,但 AI 生成的程式碼所產生的漏洞數量是人工撰寫程式碼的 1.7 倍。更多程式碼意味著每次掃描有更多發現、待處理積壓持續增長,以及安全團隊被迫在嚴謹性與速度之間取捨。
- 能見度:驅動開發的 AI 元件——模型、資料集、MCP 伺服器、代理框架和提示詞函式庫——在未經正式審查或治理的情況下進入程式碼庫。大多數組織不清楚自己正在運行哪些 AI 資產、它們嵌入在何處,或它們帶來何種風險。這個缺口是有代價的:超過 75% 的組織在過去一年內經歷過軟體供應鏈攻擊,因為每個新的 AI 元件都引入了潛在的攻擊路徑。
隨著開發速度加快,這些未受管理的 AI 元件的累積速度,已超過安全團隊的評估能力,使 AppSec 程式超出其設計的限制。

軟體供應鏈中的影子 AI 問題
這個缺口的存在,是因為傳統 AppSec 是為軟體構建模組是程式碼、函式庫和組態設定的世界所打造的。那個世界依然存在,但現在它與大多數工具無法看見的 AI 元件平行供應鏈並行運作。
如今,一個典型的 AI 驅動應用程式可能包含:從公開模型庫引入的微調 LLM、能自主呼叫外部工具的代理框架、將應用程式連接到即時資料來源的 MCP 伺服器、從敏感內部文件生成的嵌入向量,以及寫死在組態檔中的系統提示詞。
這些都不會出現在標準 SBOM(軟體物料清單)中,只有少數會在標準程式碼掃描中被標記。每一項都引入了不同的風險,從模型投毒(model poisoning)和未驗證的權重,到不安全的自主工具呼叫和暴露的資料集。
三股力量正在使情況惡化:
- 能見度正在崩潰。大多數組織無法完整盤點哪些 AI 資產正在使用、它們位於何處,或它們帶來何種風險。這與開源治理的早期情況如出一轍,但採用速度更快、元件的風險更高。
- 工具鏈已擴展。每個模型、資料集、MCP 伺服器、API 和開源依賴項都創造了潛在的攻擊路徑。這個不斷增長的依賴網絡增加了複雜性和暴露面。
- 影子 AI 是新的影子 IT。就像影子 IT 在雲端時代造成治理盲點一樣,開發人員和 DevOps 團隊正在採用 AI 工具、模型和插件,而未經正式安全審查——往往是因為尚未建立任何審查流程。
攻擊面並非理論上的。歐盟 AI 法案、ISO 42001 和 NIST AI RMF 現已將 AI 元件治理視為合規要求。如果您的 AppSec 程式無法回答「軟體中有哪些 AI」、「它們在哪裡」以及「它們做什麼」,您就存在缺口。
現有方法為何不足
幾家廠商已嘗試解決 AI 安全問題,但結果對 AppSec 團隊而言並不理想。
- 雲端態勢工具透過服務和基礎設施暴露的視角看待 AI。這些工具有其用處,但無法看見直接嵌入程式碼和組態設定中的內容。
- 製品層級掃描器審查模型檔案是否含有惡意內容,但無法提供這些模型如何串接進您的應用程式的能見度。
- SCA 擴充功能在套件清單中識別開源 LLM 依賴項,但無法理解代理框架、MCP 伺服器、嵌入的提示詞或資料集引用。
最重要的是,依賴 AI 推論來偵測 AI 的工具,引入了正是令稽核人員擔憂的那種不確定性。如果您的合規報告完全基於概率性偵測,它就不具備稽核就緒性。
要填補這個缺口,您需要一種根本不同的發現方法。
確定性發現:看見真正存在的內容
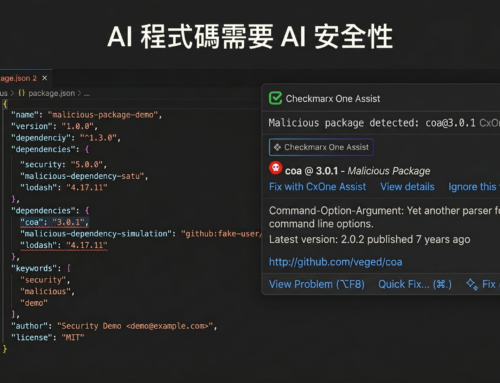
Checkmarx AI 供應鏈安全採取不同的方法:以程式碼為先的確定性偵測與高精準度掃描。它不是推斷 AI 資產的存在,而是直接從匯入、清單、檔案路徑和組態中讀取——這與開發人員傳統上了解程式碼庫依賴什麼所遵循的信號相同。
這意味著:
- LLM 和模型引用透過程式碼和組態中的識別符來識別,而非從模式猜測
- 代理框架從匯入和初始化程式碼中偵測
- MCP 伺服器從組態和整合點發現
- 資料集和嵌入向量從來源和清單中的引用追蹤
- 系統提示詞從寫死的字串和組態檔中浮現
結果是一份完整、可稽核的 AI 資產清單,而非概率性的最佳猜測。每個發現都可以追溯到特定的程式碼行或組態條目,這在您向合規稽核人員呈報結果或向開發人員解釋發現時至關重要。
專為 AI 特定威脅設計的風險評估
能見度有助於填補缺口,但並不能解決量的問題。更多資產意味著更多潛在風險、更多發現,以及更多決策——現在還延伸到一整類全新的元件。
一旦知道哪些 AI 資產存在,您仍需了解它們引入了哪些風險,以及如何大規模應對。
Checkmarx AI 供應鏈安全評估傳統 AppSec 工具無法發現的 AI 特定供應鏈風險,包括:
- 模型投毒和未驗證的權重:從公開來源引入未經完整性驗證的模型,可能在訓練過程中攜帶惡意內容或後門。LLM 安全性掃描器識別 ML 製品(PyTorch 檔案、GGUF、H5 等)並評估反序列化和執行風險。
- 未固定的模型版本:浮動的模型引用(AI 版本的套件清單中的 *)讓上游更新悄悄改變應用程式行為。版本固定作為政策要求強制執行。
- 不安全的自主代理:在未適當範圍約束的情況下呼叫外部工具的代理,會創造 AI 系統特有的執行風險。這些會作為資產清單的一部分被呈現和評估。
- 暴露的資料集和嵌入向量:用於微調或 RAG 流水線的資料集,若未適當限定範圍,可能暴露敏感的內部資訊。資料集引用被追蹤為具有自身風險特徵的一級資產。
- 資料集暴露和授權違規:開源模型和資料集帶有與傳統軟體授權顯著不同的授權義務。AI 資產元資料包含授權資訊,可在不合規元件出貨前強制執行政策。
相同的工作流程,擴展以涵蓋 AI
新增安全工具通常意味著增加摩擦:一個需要學習的新平台、一組需要分類的新警報、一個需要與其他一切並行維護的新報告工作流程。這正是 AppSec 整合至關重要的地方。
Checkmarx AI 供應鏈安全直接內建於 Checkmarx One——您已在其中管理漏洞、執行 SAST 和 SCA、強制執行政策並生成合規報告的同一平台。無需獨立產品或並行工作流程。
在實踐中,這意味著:
- AI 元件與傳統發現並排呈現在相同的儀表板中,使用相同的分類工作流程。
- 政策強制執行在拉取請求和 CI/CD 中進行,方式與您今日在開源漏洞或 SAST 發現上設置閘道相同。您可以封鎖未核准的模型、標記不安全的代理,或要求版本固定,而無需編寫自訂自動化。
- AI-BOM 生成意味著 AI 資產與您的 OSS 依賴項出現在相同的物料清單中,附帶來源、授權、依賴關係和風險元資料。
- ASPM 工作流程——包括風險協調、分析和儀表板——自然延伸以涵蓋 AI 元件,無需獨立的儀器。
- API 和 CLI 支援讓 AI 掃描融入現有的流水線自動化,無需新的整合。
目標是在不增加摩擦的情況下實現責任制。您並非在取代 AppSec 工作流程,而只是將其擴展以涵蓋一類新的元件。
您的 AppSec 團隊能獲得什麼
最終結果是對現有 AppSec 程式的實用擴展。
- 企業範圍內完整的 AI 資產清單。程式碼庫中存在的每個 LLM、代理框架、MCP 伺服器、資料集、嵌入向量和系統提示詞,都從程式碼和組態中確定性地呈現,彙整為可搜索、可稽核的目錄。
- AI 特定風險評估。模型投毒、未驗證的權重、不安全的代理、暴露的資料集、未固定的版本——以有證據支持的發現和可操作的修復指引進行偵測。
- 法規就緒性。AI-BOM 與針對歐盟 AI 法案、ISO 42001、NIST AI RMF 和 OWASP LLM Top 10 的合規態勢追蹤對齊,並在稽核人員詢問時隨時可導出。
- 在開發人員工作流程中強制執行政策。核准的模型清單、框架允許清單、版本固定要求——在拉取請求和 CI/CD 中強制執行,而非事後補救。
- 無新平台開銷。一切都在 Checkmarx One 中,使用您的團隊已依賴的相同權限、儀表板和報告。
AppSec 的核心結論
AI 元件已改變了軟體的構成,現在成為軟體供應鏈的一部分。問題不在於它們是否存在,而在於您的 AppSec 程式是否能處理它們所帶來的能見度和量的問題。
治理 AI 供應鏈不再是可選項。您的 AppSec 程式需要能見度、工具和工作流程整合,以跟上步伐。Checkmarx AI 供應鏈安全正是為此而生:確定性發現、以證據為基礎的風險評估,以及直接內建於開發人員工作流程的端到端治理。它與您現有的流水線整合,讓您在程式碼、依賴項、模型和執行環境之間獲得統一的風險圖景,而無需管理另一個孤立系統。
如果這個缺口聽起來很熟悉,它很可能已存在於您組織的環境中。好消息是:它是可以解決的,且不會破壞您已建立的 AppSec 程式。